Earlier this year, I decided to dive into machine learning and find out what all the hype was about. A good starting point seemed to be K-means clustering as my unsupervised machine learning algorithm.
Ok, so I have the tools, now what? I knew I wanted to work with text (i.e., corpus). Somehow classifying documents into sentiment analysis. Something that I can talk with other Data Scientist and get there input on. Through my search, I happened to land on the Enron Email Corpus, which I ended up working on. It’s the largest public data source of it’s kind. Rumor has it, it’s the set that Siri was trained on from DARPA? I couldn’t find anything else publically available to me. However, this wasn’t the reason why I delved into it.
As I mentioned my project to friends (several — way too young to remember), it dawned on me, they have no idea. Most of them were baby’s during this time (really, they were like 10–12 years old). This is a great time to work on this project, bring this former mainstay to light. If anything — get a better understanding of K-means clustering.
The Data
All research I did landed on the Carnegie Mellon University — School of Computer Science.
https://www.cs.cmu.edu/~enron/
Evidently, they worked on this quite a bit back in the mid-2000s. The number of emails was staggering. Over 500,000 emails. That’s a ton. However, I did not want to spend my time cleaning, organizing, or categorizing them. Luckily, CMU students did most of that, but I won’t be using their categorized emails. I won ‘t be classifying — simply finding correlations between words throughout the corpus — clusters.
Through further online research, I found Brian Ray’s work the Enron Corpus. He actually placed them in a beautifully laid out, over 2 gigs, CSV files. That’s a ton of data. Better get to work.
Data Cleaning
I’m not classifying but letting my model determine the cluster of most interesting words. To be able to explore the data further. I ended up dropping most of my categories, except for the body of the text and the date. Don’t get me wrong, there was still data cleaning that I had to perform. Typical cleaning, duplicates, NaN’s, etc.…
Vectorizing
To use my clustering algorithm, I found the need to vectorize my corpus. I started using TFIDF (term frequency-inverse document frequency). However, for the end presentations, it was easier for me to present “counts” and not term-frequencies. So, I switched to CountVectorizing instead in my pre-processing.
Model
As I mentioned earlier, I knew I would be clustering my corpus, and K-means clustering was an easy entreé into machine learning. Pretty straight forward. I won’t bore you with the details here, but I’ve provided a link to the Enron Email Analysis public GitHub repo below:
https://github.com/adriancampos1/Enron_Email_Analysis
Resources
You can find my Jupyter Notebooks there as well as the end data source that I used for the project. Also, links to the complete undoctored email set, if that’s your jam.
https://data.world/brianray/enron-email-dataset
Findings
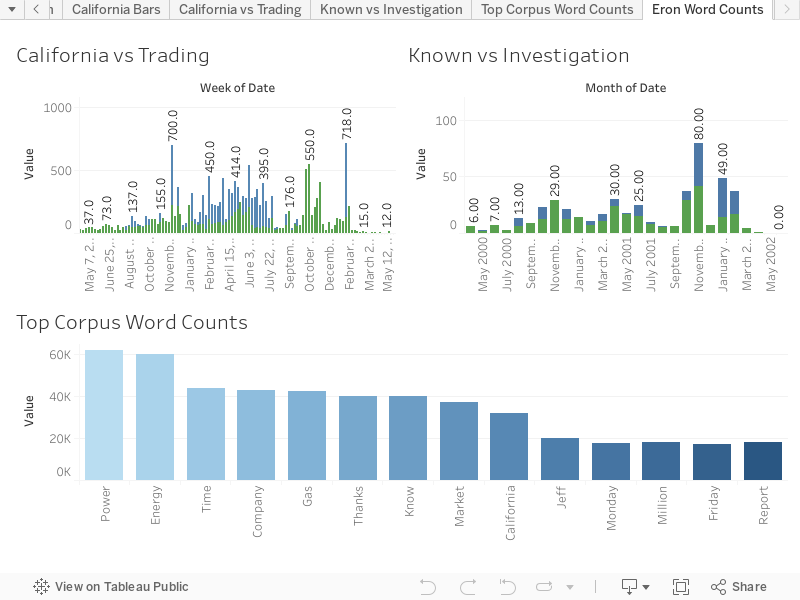
My K-means algorithm brought out some interesting, but not surprising clusters. For example, I found a cluster with California, Cali, CA, and trade, traders, trading in one cluster. This would make sense as Enron executives encouraged market engagement with specific traders to drive the cost of energy higher. Its effect was the 2001 California energy crises, causing high energy prices and blackouts throughout the state.
Other clusters found legislature, know, knowing, knowledge, investigation, commodities, etc.. A cluster worthy of further investigation.
Wrap
My Enron Email Analysis project was short work on the exploration of Machine Learning through unsupervised K-means clustering. Further investigation on the dataset can definitely bring forth additional findings. This corpus is still utilized today to train NLP models. If you’re looking to work on text or sentiment analysis, I will steer you in the direction of this corpus. You’ll find it challenging.
Visualizations